The 404 Opportunity

404 Is a Handoff, Not a Dead End
When a visitor follows a broken link, the server already knows what content the site has, it just fails to put that knowledge to use. The default 404 is a blank receipt, and nginx delivers a black-on-white apology before walking away from a conversation it could have kept going.
Site operators track 404s obsessively for SEO reasons, patching redirects and chasing crawler complaints because search rankings punish dead links, but the users who hit those links before the fix lands still get nothing. On the agentic web this problem compounds, because AI agents follow links too and a generic 404 to an agent is a silent stop with no hint, no alternative, and no next step. Most of those agents do not execute JavaScript either, so any client-side recovery layer you might have added never actually runs for them.
Prior Art
While sketching this out I came across agent404.dev by Bharath, and it is a well designed project. A single script tag on your 404 page returns structured JSON-LD suggestions ranked by semantic embeddings, so AI clients can recover from dead links instead of failing outright. The license is MIT, the framing is exactly right, and the hosted option makes it trivial to adopt.
It was not what I had planned to build though, because my target was the class of clients that never runs JavaScript in the first place: Claude browsing, curl, MCP fetchers, RAG scrapers, and anything else parsing HTTP responses directly. A script tag cannot help any of them, since the suggestions only materialize after a page renders in a browser. So rather than reinvent the client-side piece, I built a sibling that handles the same problem from the server side, with response shapes designed to stay compatible with what agent404.dev already produces.
agent404-server
agent404-server is a reverse-proxy 404 handler that sits behind nginx. When try_files runs out of options, the request falls through to a small Node service that inspects it and responds with semantics shaped by HTTP itself, rather than a body the client may or may not bother to parse.
| Confidence | HTTP Status | What the client gets |
|---|---|---|
| Above 0.85 | 302 + Location | Follows automatically, zero parsing needed |
| 0.5 to 0.85 | 300 Multiple Choices | Ranked suggestions in JSON |
| Below 0.5 | 404 | Suggestion list and a pointer to the site's MCP endpoint |
Every response carries an X-Match-Confidence header, so an agent can decide how much to trust the redirect before it even looks at the body, while human visitors get an HTML page with a countdown scaled to the confidence level and a cancel link if they want to override it.
korm.co is a static site, which is why try_files is the hook here: nginx walks the filesystem and falls through to the handler only when nothing matches. On a dynamic site the upstream app answers every request, so the equivalent wiring is proxy_intercept_errors on with error_page 404 = @smart_404, letting nginx catch the app's own 404 responses and route them to the same service. The Node service and its matching logic stay identical either way, only the nginx glue changes.
Matching
Where agent404.dev ranks candidates with semantic embeddings, agent404-server takes the opposite bet. korm.co has eleven pages, the 404 endpoint is a magnet for scanner traffic, and typos are the high-volume case for real users, so loading an embedding model or calling a vector store on every request is a lot of machinery to rank a tiny set. The pipeline stays deterministic and dependency-free, running entirely on string-level signals against a content index built from the sitemap and page titles at startup.
A request flows through five stages in sequence:
- Normalize the path by lowercasing, stripping trailing slashes, URL-decoding, and collapsing duplicate slashes.
- Apply known transforms, like rewriting
/blog/*to/media/*or/aboutto/bio. - Compute Levenshtein distance against every known path for a fuzzy score.
- Fuzzy match the last segment against article slugs.
- Tokenize the path, drop stopwords, and look the tokens up against a keyword index derived from page titles.
Scores are capped and merged, the top five survive, and ties break on sitemap priority. The whole pass finishes in a few milliseconds. For the genuinely semantic cases, where the path shares no surface overlap with the right page, an LLM escape hatch handles the rest. On a small catalog like korm.co's, that means handing the full content index to a Haiku-class model in a single prompt and asking which page the user meant. On a site with thousands of pages, the catalog no longer fits in context, so a local RAG step using embeddings narrows the candidate set first and the LLM picks from that short list. Client-side embeddings via agent404.dev cover that same gap from the other direction, which is another reason not to duplicate them on the server.
Telling Humans from Agents
Before it picks a response format, the service scores the request against a small set of weighted header signals to decide whether a human or an agent is on the other end.
| Signal | Weight |
|---|---|
| Bot, agent, Claude, or GPT in User-Agent | +0.5 |
| curl, wget, httpie | +0.3 |
Accept: application/json only | +0.3 |
| Missing Accept-Language | +0.1 |
| Has Sec-Fetch headers | -0.2 |
Accept: text/html first | -0.2 |
Anything above 0.6 is treated as an agent, uncertainty defaults to human, and obvious scanner probes like /wp-admin or /.env never reach the matcher at all, because a static blocklist rejects them at the door and returns a plain 404 with zero processing.
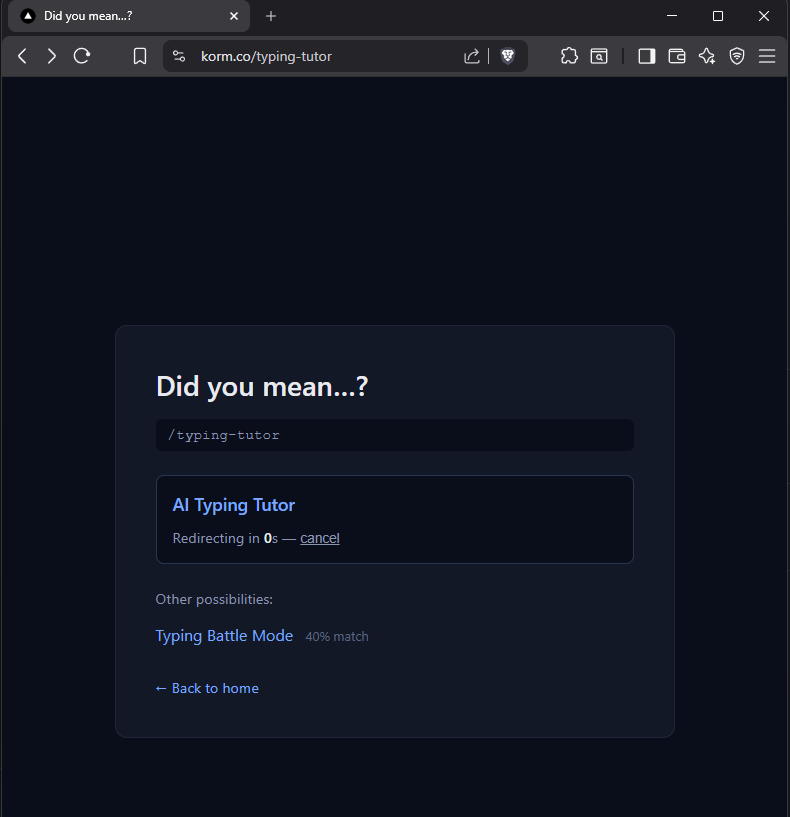
Live on korm.co
A request for /typing-tutor used to return the default nginx page with no onward path, and now it matches /media/ai-typing-tutor at high confidence and redirects, with a visible countdown and a cancel link for any human who wants to bail.
An agent hitting the same URL with Accept: application/json gets a 302 with a real Location header, a JSON body listing alternatives, and an X-Match-Confidence score it can read before touching anything else. From there the agent chooses what to do based on that score, following the redirect when confidence is high, picking from the alternatives when it is not, and never having to parse a body it did not ask for in order to make the call.
Low-confidence 404 responses also carry a pointer to korm.co's MCP endpoint, which turns a broken link into a natural handoff from a failed URL guess into full agent discovery: instead of a dead end, the agent gets a machine-readable entry point to the rest of the site through the same protocol it already knows how to speak.
Hoping to Collaborate
agent404.dev solves the client-side case cleanly and agent404-server solves the server-side case for the clients that never run scripts, with response shapes kept compatible on purpose so the two can run together or independently as a full picture of what a 404 can become on the agentic web. I would much rather this become a shared project than a parallel one, so the code is open at github.com/kormco/agent404-server, the live endpoint is korm.co itself, and I am hopeful the author of agent404.dev and I can collaborate on where this goes next.