Layers of AI Practice

When someone says they are "good with AI," what does that actually mean? Since AI is changing so quickly, so too is the answer.
Researching the topic I found Anthropic's AI Fluency framework, built with Rick Dakan and Joseph Feller, which defines fluency as the ability to work effectively, efficiently, ethically, and safely with AI. It does this through four competencies, the 4Ds: Delegation, Description, Discernment, and Diligence. It is a real framework, it is teachable, and it is a shared vocabulary.
It still does not tell you how good someone is with AI. Nothing yet does. Anthropic's own AI Fluency Index measures eleven observable behaviors in conversation transcripts and explicitly refuses to assign a person a score. The credible attempts are honest about what they cannot do. Below is how I think about the layers anyway, what each one looks like in practice, and why I think measurement is still genuinely open. This matters for naming our own strengths and weaknesses, for evaluating the people we hire, for building the way we teach.
Competency Is Not the Same As State
The 4D framework is competency-based. Delegation is a skill, Description is a skill, Discernment is a skill, Diligence is a skill. These travel with the person. If you have them, you can apply them in a chat window, in a coding harness, or during a model training run. They are stable.
What competencies do not capture is where someone is actually working. Two strong delegators can sit in very different places. One has only ever typed into a chat box or tabbed for auto-completion. The other has wired Claude into their daily workflow with tools, evaluation harnesses, and feedback loops. Same competency, different state. If you watched the first person work, you would see a browser tab. If you watched the second, you would see a terminal full of running processes, a context file under version control, and a channel where a small set of agents reports in.
They are not at the same place. What is missing is a state-based view to sit alongside the competency one. Where is this person working from. What surrounds the model when they use it. What feedback loops are in place. That gap is what I've tried to represent based on my own journey, but it isn't meant to be authoritative.
Four Layers, Not a Ladder
There are four layers I notice when I watch people work with AI. I think of them as parallel tracks, not as floors of a building.
- Assistant. Talking to a model and getting useful work out of it. Even automating or self-improving à la Claw.
- Coder. Designing and generating real things (code, documents, media) with AI in the loop. Generative design and production. Automating the production or creating factories of things.
- Agent. Composing apps that reason, with tracing, evals, and harnesses on top of models. Sophisticated long-running processes learning from their behavior.
- Model. Working with weights, datasets, fine-tunes, inference, and training at the model level. Benchmarks drive future model development on size, latency, cost, and other dimensions.
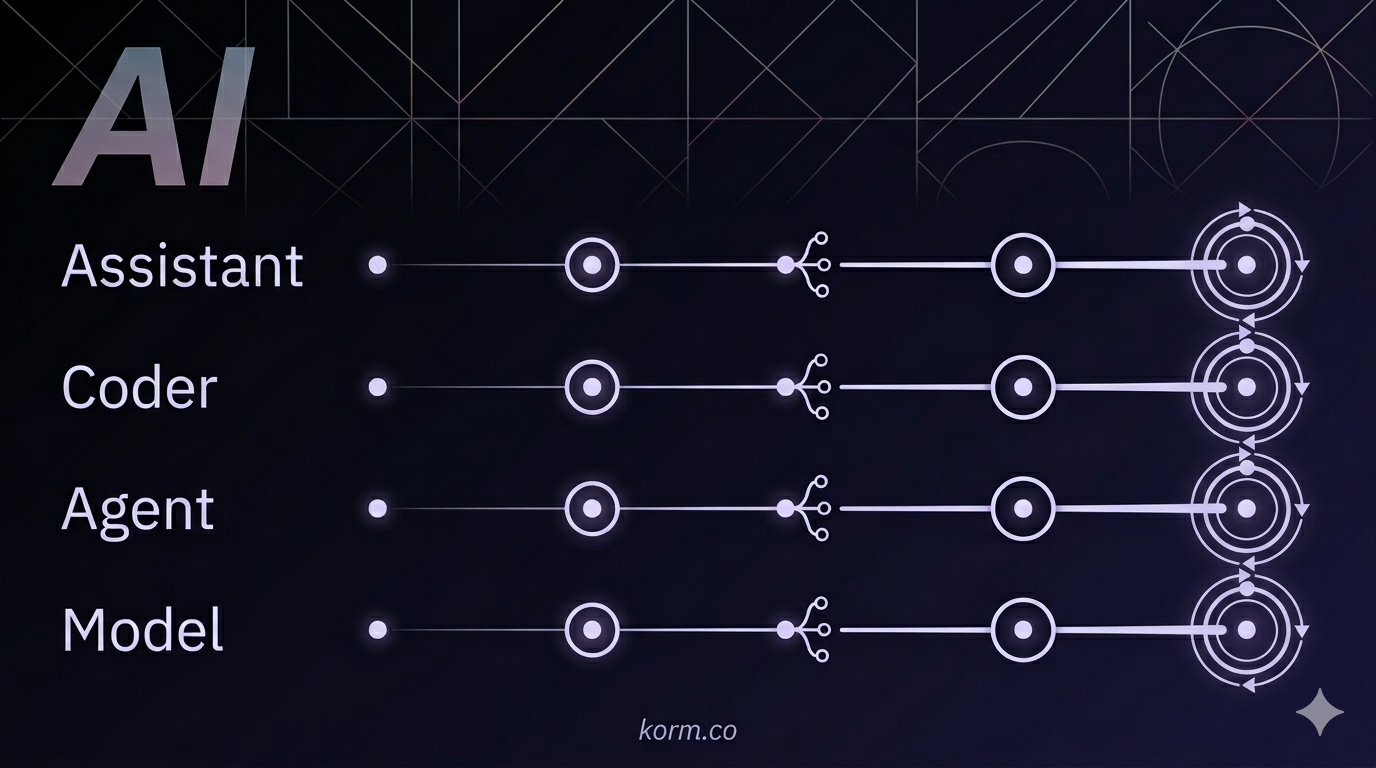
Nobody is required to move up or down. You can have a happy and sophisticated AI life working in any layer. The presence of Coder, Agent, and Model is not a judgment about Assistant being immature. They are different work, team sports. All layers can be automated and made into self-improving loops.
Individual people easily sit in different layers for different tasks. A frontend engineer might live in Coder for their day job, dabble in Assistant personally, and never touch Agent or Model. A research scientist or domain expert might work in Model and never write a line of production application code. Both can be advanced in different ways with various depths at each level making up their skill matrix.
The published thing closest to Coder is MindStudio's Five Levels of Agentic Coding, which describes the same progression I am about to walk through but specifically for software development: Autocomplete, Chat-Assisted, Agentic, Harness-Driven, and Dark Factory. The pattern they identified for coding generalizes. It shows up in writing, in research, in design, in operations.
The published thing closest to Agent is Anthropic's Building Effective Agents essay, which lays out workflow patterns from simple prompt chaining up through orchestrator-workers and evaluator-optimizer loops. Their direct advice is worth quoting: "Start with simple prompts, optimize them with comprehensive evaluation, and add multi-step agentic systems only when simpler solutions fall short." That is the same no-judgment stance I am taking on the layers above. Most work does not need an autonomous agent. Some does.
LangChain has started calling Agent-layer work Agent Engineering and frames it as the blend of three existing skill sets rather than a new job title: product thinking, engineering, and data science. The actual work is a loop of build, test, ship, observe, refine. Like the layer below it, agent engineering is a team sport. The reason LangChain has to argue it is a discipline at all is the same reason this post exists. People are doing the work, and there is no shared vocabulary yet for what they are doing.
Same Five Phases Above the Model Layer
Each layer has its own internal progression, and it looks almost identical across all four, which adds to our confusion. The five phases I keep noticing are: Prompt, Context, Tools, Automate, Self-Improve.
- Prompt. You type a question into a box and accept whatever comes back.
- Context. You start feeding the model the right material before asking. A pasted spec, a file, a long conversation.
- Tools. You give the model the ability to do things outside its own output. Search, run code, call APIs, read your files.
- Automate. You take yourself out of the moment. The system runs on a schedule, on an event, or in the background while you do something else.
- Self-Improve. The system uses its own output to get better, through evals, datasets, tracing, feedback loops, memories, or training.
If you reread that list with "AI assistant" in mind, you get the MindStudio coding levels. If you reread it with "agent in production" in mind, you get the path LangChain recommends for RAG and agent pipelines. The same five phases keep coming back because they describe what you do when you take a thing that works once and try to make it work reliably.
Model is the exception. The five phases bend when you push them down to the weights layer. There is no Prompt phase when you are training; you are feeding data, not asking questions. Context has a rough analog in dataset curation and labeling, but it is not the same practice. Tools are something you train a model for, not something you hand the model during training. Automate is the default state of any training run, not a stage you reach. Only Self-Improve translates cleanly with Reinforcement Learning. The Model layer has its own shape and its own vocabulary. The phases generalize well enough at the three layers above to be useful. Open-source has made the Model layer reachable for people outside the frontier labs.
This gives me a spatial mapping. It gives me a vocabulary. It does not give me a measurement.
Measurement Is Open
In an attempt to quantify everything, we must publish a leaderboard! But which artifacts of our work, or which slice of our telemetry, should we consider? And are we to be traced for it? How many tokens do they consume in a week? Across how many different models? Do they use a harness or just a chat window? Do they write context files? Do they commit code that an agent helped generate? Do they have evals? Is there Python in their day? Hard to discern signal from noise.

Unfortunately this requires mass surveillance to figure out. A token footprint tells you something. It also requires somebody to be reading that to understand context. The reason no credible group has published a personal AI fluency scoring system is not that the signals are not there. It is that collecting them at the level of an individual is expensive (lack of standardization), invasive, or difficult to accept.
Self-Improvement Without the Score
The point of all of this is not to give the world a way to score you. It is to give you a way to see yourself. The same five phases (Prompt, Context, Tools, Automate, Self-Improve) show up across Assistant, Coder, and Agent. The Model layer has its own progression but the same idea applies: you can be deep or shallow at each stage. That is close to twenty cells to look at honestly. In which are you deep. In which are you shallow. Where do you stop, and is that because the work does not need more, or because you have not built the muscle yet.
Growth here is not climbing a ladder. It is picking the next phase to push into, in the layer where it matters for what you are actually trying to do. If you live in Coder and have never written a context file, that is the next move. If you live in Agent and have a harness but no evals, that is a step you can take. You do not need anyone to certify that. You only need to look.
Note: deeper dives on AI coding factories and on context synchronization across the layers will follow.